 940
940
 0
0
 2022-12-16
2022-12-16
 2022-12-16
2022-12-16
本篇学习报告基于cvpr 2017的文章:
作者为目标检测任务提出了一种多尺度的特征融合算法:fpn(feature pyramid networks),也就是近些年广泛运用的特征金字塔结构。原来多数的目标检测算法都只是采用顶层的特征图做预测。实际上我们只知道,低层的(low-level)特征图虽然语义信息较少,但是目标位置准确,与高层(high-level)特征图相反。之前其实也有一些多尺度特征融合算法,而fpn的特别之处在于融合前后用于预测的特征图个数是不变的,而在此之前的融合算法则是将多个不同尺度的特征图融合成一个进行检测。
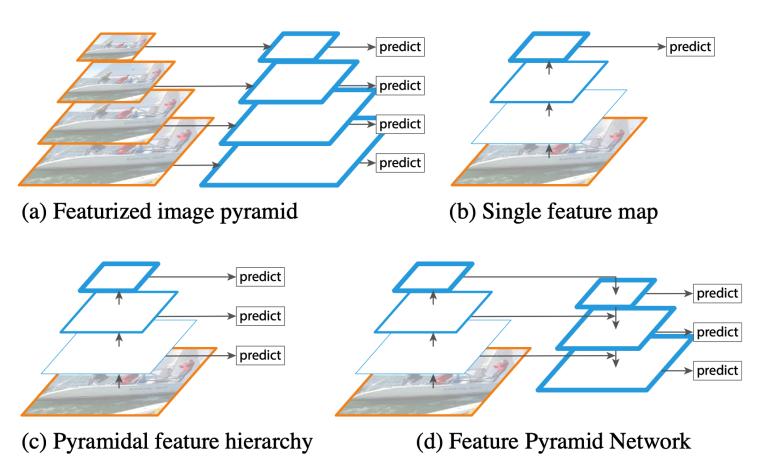
上图展示了4种特征利用方式:
在fpn之前的特征融合方式如下图所示,和fpn一样采用了skip-connection的结构并且是自顶向下进行特征融合,但仅使用了最后一层融合结果用于预测。
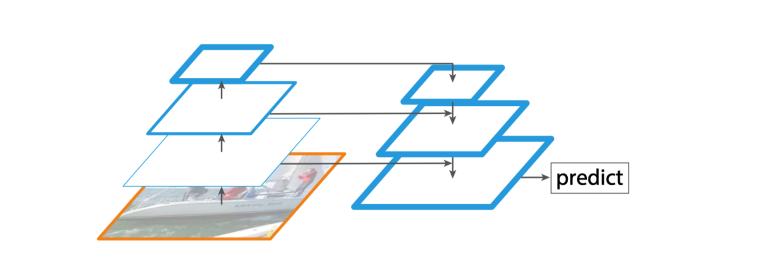
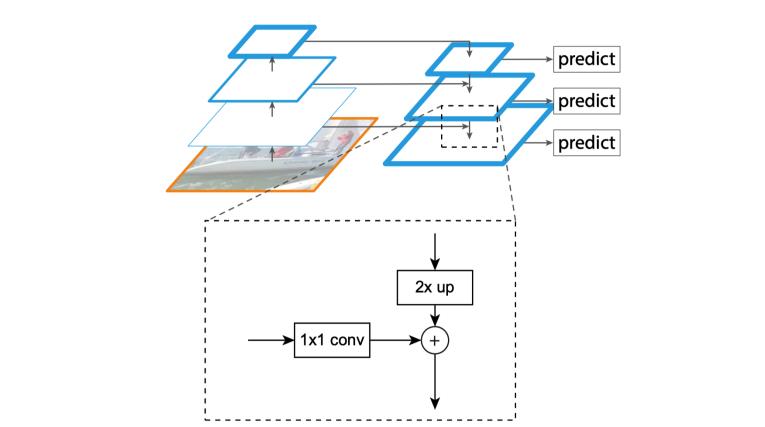
fpn算法的大致结构如下图所示,一个「自底向上」的路线,一个「自顶向下」的路线,还有一个横向连接结构(lateral connection),图中放大区域就是横向连接,1*1卷积核能够调整通道数使得不同层的特征图能够融合。自底向上其实就是网络的前向过程,在这个过程中,特征图(feature map)的大小在经过某些层后会改变,而经过其他一些层的时候不会改变,作者将不改变特征图大小的层归位一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能够构成特征金字塔。自顶向下的过程采样上采样(upsampling)方式,而横向连接则是将上采样的结果和自底向上生成的相同大小的特征图进行融合(merge)。实际上,在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是为了消除上采样的混叠效应(aliasing effect)。
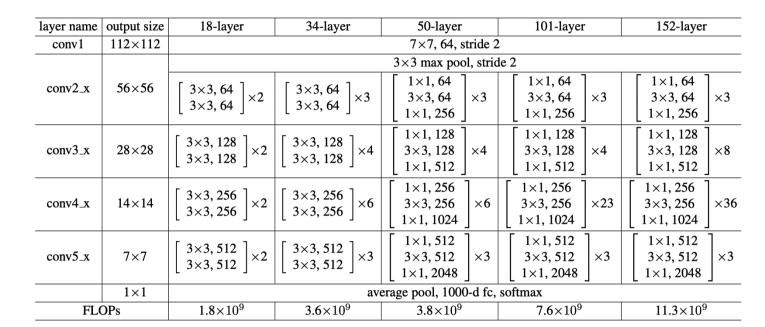
我们用resnet举一个例子来说明什么是stage,下图是resnet的网络结构组成示意图,可以看到第二列output size共变化了5次(fc层不算),其实就分别对应着5个stage,比如conv2_x这一层的输出就是p2,p是指pyramid,特征金字塔自底向上的第2层。
作者将fpn结构放在rpn(region proposal network)中用于生成proposal(原意为“建议”,这里指可能含有目标的区域),原来的rpn网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将fpn嵌在rpn网络中,生成不同尺度特征并融合作为rpn网络的输入。在每一个scale层,都定义了不同大小的anchor,对于p2,p3,p4,p5,p6这些层,定义anchor的大小分别为32*32, 64*64, 128*128, 256*256,512*512,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1,所以整个特征金字塔有15种anchor。正负样本的界定和faster r-cnn差不多,如果某个anchor和一个给定的ground truth有最高的iou或者和任意一个ground truth的iou都大于0.7,则是正样本,如果一个anchor和任意一个ground truth的iou都小于0.3,则为负样本,其余的丢弃。
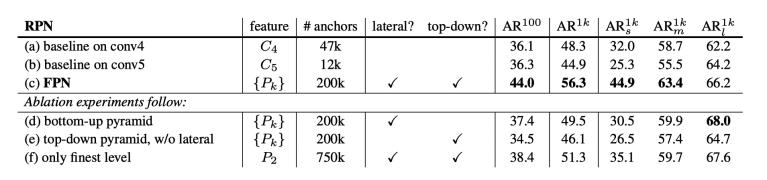
接下来看看加入fpn的rpn网络的有效性,如下表table1。网络这些结果都是基于resnet-50。评价标准采用ar,ar表示average recall,ar右上角的100表示每张图像有100个anchor,ar的右下角s,m,l表示coco数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。从(a)(b)(c)的对比可以看出fpn的作用确实很明显。另外(a)和(b)的对比可以看出高层特征并非比低一层的特征有效。(d)表示只有横向连接,而没有自顶向下的过程,也就是仅仅对自底向上(bottom-up)的每一层结果做一个1*1的横向连接和3*3的卷积得到最终的结果,有点像fig1的(b)。从feature列可以看出预测还是分层独立的。作者推测(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。(e)表示有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。(f)采用仅最后一层的输出做预测,即经过多次特征上采样和融合到最后一步生成的特征用于预测,主要是为了证明金字塔分层独立预测的表达能力。显然效果不如fpn好,原因在于rpn网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外(f)有更多的anchor,说明增加anchor的数量并不能有效提高准确率。
文中的其他类似实验就不一一解读了。
作者提出的fpn(feature pyramid network)结构同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
撰稿人:蓝福财
指导老师:何乐为






