 837
837
 0
0
 2022-12-30
2022-12-30
 2022-12-30
2022-12-30
本篇学习报告来源:《plug-and-play domain adaptation for cross-subject eeg-based emotion recognition》。作者设计了一种仅用少量目标域数据进行微调的域适应方法。准确率高的同时大大缩短了校准时间。
脑电数据个体差异性巨大,常规方法是在测试阶段之前,从新受试者中收集大量数据,并对其进行标记,并用这些数据自定义分类器参数。不幸的是,这种需求是耗时的,并导致较差的用户体验,这使得模型不太实用。另一种途径是使用迁移学习方法来处理个体差异。迁移学习根据模型训练阶段是否使用目标领域的数据,大致可以分为领域适应(da)和领域概化(dg)。在情感识别的实际应用中,由于da使用所有目标数据,效率较低,dg不依赖目标主体的任何信息,泛化能力较差。与da和dg的极端观点相反,在实时识别开始前引入短期校准阶段是可以接受的,也是必要的。然而,现有的研究表明,如果训练数据的数量相对于特征向量的维数较小,模型很可能会崩溃。因此,在有限的目标训练数据下实现良好的da结果是一个挑战。
ppda的框架如图1所示。整个结构可分为训练阶段、校准阶段和测试阶段。在训练阶段,首先采用基于注意的池化方法,利用脑电信号关键通道和波段的空间信息。然后,采用基于长短期记忆的编解码器方案研究时间依赖性。用共享编码器es和私有编码器e1 ~ np来分别捕获被试不变的情感表征和私有成分。通过使用编码器的输出,我们进一步建立了一个共享分类器cs和单个分类器c1 ~ np来同时识别情绪。在这一阶段,只使用标记的源数据来训练模型。在校准阶段,我们使用一个收集的最开始的数据,在训练过的es和解码器ds的帮助下,对新被试的私有组件进行建模。在测试阶段,不仅可以像域泛化方法那样使用共享分类器的管道,还可以通过与私有源组件的相似性从私有分类器中获取知识。最后,应用分类器融合策略对两种识别结果进行融合。
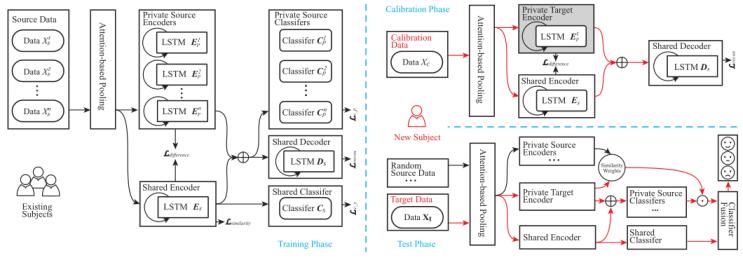
图1 整个结构可分为训练阶段、校准阶段和测试阶段。训练阶段的子模块将通过几个损失函数的组合进行优化。在校准阶段,只有灰色突出显示的私有目标编码器将被更新。在测试阶段,最终的预测将由两条管道完成。红色方向线表示新被试的数据流,黑色方向线表示来源。
假设xt∈rm作为t时刻的一个eeg特征向量的注释,其中m为特征维数。xt的每一维数代表来自某波段特定信道的信息。我们得到加权脑电图特征向量~xt,其中~xt=at (xt), at表示基于注意的池化。将xt输入到单层全连通神经网络中,通过softmax函数测量表示xt各维重要性的归一化权向量αt∈rm,为:
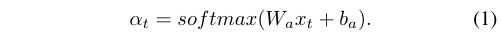
在此之后,计算~xt作为加权后的新eeg特征。
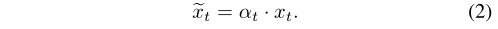
对于αt中的每个元素,数值越大,其对应的维度,即该波段的通道越重要。权值矩阵wa∈rm×m和偏差向量ba∈rm在训练过程中被随机初始化和微调。
选择lstm来构建编码器-解码器架构。对于输入序列中的每个元素,lstm单元计算式(3)中的函数:
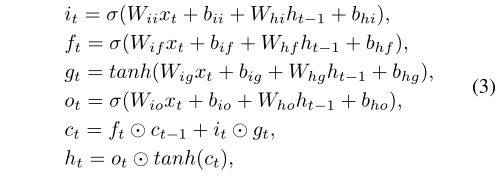
其中it, ft, gt, ot是输入,遗忘,单元格和输出门。ht和ct分别为t时刻的隐藏状态和单元状态,ht−1为t−1时刻的层隐藏状态或最开始的初始隐藏状态。σ代表sigmoid函数。
考虑一个时间步长为l的eeg序列x = {x1, x2,····,xl},其中每个点xi∈rm是由一个被试者的注意机制调制的m维eeg特征。利用ti时刻的eeg特征xi和共享编码器ti−1时刻的隐藏状态hi−1 es来计算hies。同时计算私有编码器的隐藏状态hiep。隐藏状态h4es和h4ep的组合将共享解码器的h4d初始化为:
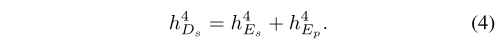
解码器则以相反的顺序重建eeg特征序列。
在训练阶段,只使用已有源域的标记脑电图数据来训练模型,目的是将损失降到最低:
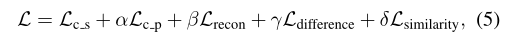
其中α,β,γ,δ是控制损失项协同作用的权衡。通过最小化情绪的交叉熵损失:
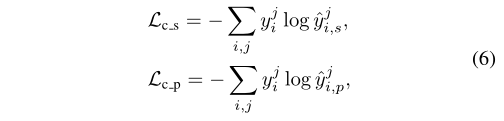
其中yj i是来自特定jth主题的输入xj i的真实情感标签。^yj i,s和^yj i,p是共享分类器和对应私有分类器的softmax预测:
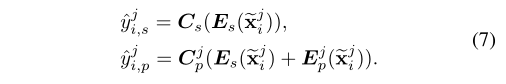
使用均方误差来计算重建损失lrecon:
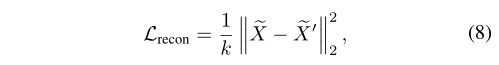
其中k是eeg特征的数量。差分损失ldifference用于鼓励共享编码器和私有编码器对输入的不同方面进行编码:
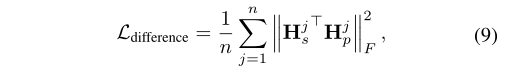
在提取被试不变情感表征的思想驱动下,我们训练了一个领域分类器cd,通过梯度反转层(grl)来混淆共享编码器。在正向传播过程中,grl作为恒等函数工作,但在反向传播时反转梯度方向。lsimilarity的计算公式为:
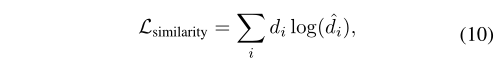
其中di为ground truth域标签,而^di = cd(cs(^xi))。
由于脑电图数据是按时间顺序记录的,只能将最开始的数据作为校准数据。首先对私有目标编码器etp的参数进行随机初始化,利用标定数据,通过公式(8)和公式(9)分别对重构损耗和不同损耗进行优化。可以认为,一旦任务确定,共享编码器es具有足够的泛化性,具有提取主题不变情感成分的能力,ds在数据重构中表现良好。因此,es和ds参数在反向传播过程中保持不变,当联合损失达到最小时,etp最能刻画当前主体的个体差异。
在测试阶段,一旦收集到目标序列xt,则从每个xjs中随机选择相同长度的数据。模型的性能是由两个管道保证的。像大多数领域泛化方法一样,使用训练过的共享分类器来保证泛化能力,如yts=cs(es(at (xt)))。对于另一个管道,计算e1 ~ np (at (x1 ~ nrand))和etp(at (xt))之间的余弦相似度,以利用私有信息。权重越高,说明分布与目标数据越相似,对分类器的信任度越高。然后通过权向量与c1 ~ np的结果向量的点积得到预测的ytp。将这两个标签通过分类器融合策略进行整合后确定最终结果。
采用loso验证策略与其它方法在seed数据集上比较。在校准阶段,丢弃情绪标签后的第一个t秒数据作为我们的校准数据。lstm的层数固定为2,隐藏大小固定为64,时间步长固定为15。情感分类器和领域分类器是单层全连接网络,隐藏维数为64。设置校准时间t为45s。t对于控制损失项协同作用的权衡,参数是随机寻找的,即α∈{k * 10−1|k∈{1,…, 9},β∈{k∗10−4|k∈{1,…,5},γ∈{k * 10−5|k∈{1,…,3}和δ∈{k * 10−2|k∈{1,…3}。采用adam优化器作为优化函数,在{2k∗10−4|k∈[−5,5]}中选择学习率。
表1 不同方法在seed上运行的结果。
atd是用于模型训练的目标数据量的缩写。
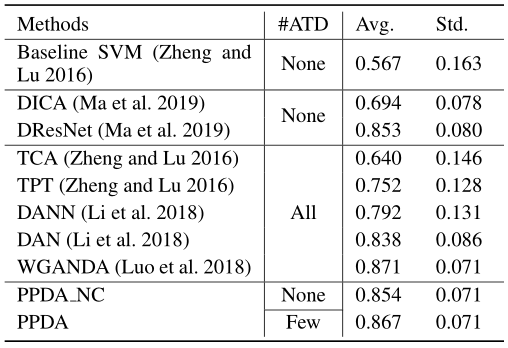
ppda得到了稳定、良好的结果,准确率约为86.7%,标准差约为0.071。如表1所示。对于在模型训练过程中不依赖任何目标数据的dg方法,如dica和dresnet,作者的模型的准确率分别提高了22.71%和1.41%,这表明即使使用少量的目标数据也会提高模型的识别性能。与da方法相比,作者的模型优于所有的da方法,除了wganda略有下降。虽然该方法的识别性能不是最优的,但在保持识别精度的同时,大大缩短了校准时间,具有重要的现实意义。省略了ppda的校准环节的模型记为ppda_nc,其他部分不变,重新运行seed实验,检验其泛化能力。识别性能的降低说明了校准阶段的重要性。
撰稿人:梁容铭
指导老师:潘家辉






