 1065
1065
 0
0
 2023-01-10
2023-01-10
 2023-01-12
2023-01-12
本篇学习报告的内容来自 deepemd: differentiable earth mover's distance for few-shot learning,该论文是cvpr 2020论文(deepemd: few-shot image classification with differentiable earth mover's distance and structured classifiers)的期刊扩展版,目前已被t-pami 2022录用。
本文为小样本学习( few-shot learning)领域的一篇论文,其中牵涉部分小样本学习概念。小样本学习是以任务(task)作为自己的训练单位,即小样本学习的实际训练集和测试集是由一个个的任务组成,为了进行区分,每个任务内部的训练集(training set)更名为支持集(support set),测试集更名为查询集(query set)。本文使用n-way-k-shot描述方法,其中n代表类别数量,k代表每一类别的样本数量。
 图1 n-way-k-shot设置。源自ravi 等人(2017)
图1 n-way-k-shot设置。源自ravi 等人(2017)
在小样本图像分类领域中,基于度量的方法通常使用特征提取网络将支持集图像和查询集图像映射到一个特征空间中,再利用度量函数(例如余弦距离和欧氏距离)直接计算支持集图像和查询集图像特征表示之间的相似度,并以此进行分类。然而,杂乱的背景和较大的类内外观变化可能会使来自同一类别的图像在特征空间中差别很大。因此本文指出,一个理想的度量学习算法应该具备使用图像局部具有可辨认性特征的能力,以及尽量减少被图像中无关区域干扰的能力。
将图像拆分成多个图块,通过emd(the earth mover's distance)度量,利用线性规划的方式寻找两幅图像各个图块之间的最佳匹配方案,并且通过交叉参照机制(cross-reference mechanism)为不同位置的图块生成不同的权重,从而提高对目标区域的注意,减少无关区域的干扰。
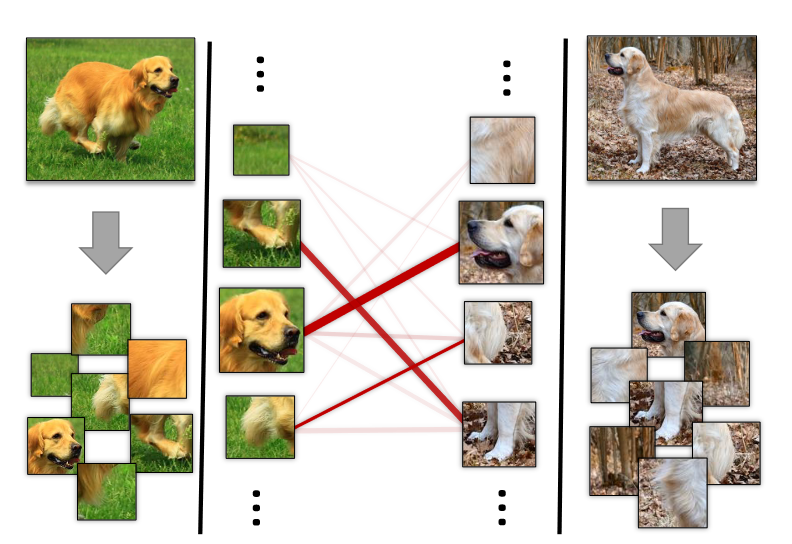
图2 使用emd度量1-shot图示
2000年,推土机距离(the earth mover's distance,emd)由yossi rubner在论文:the earth mover's distance as a metric for image retrieval 中提出,最初emd的概念用于图像检索,用来衡量两个概率分布之间的差异。(详细介绍及证明见原论文)
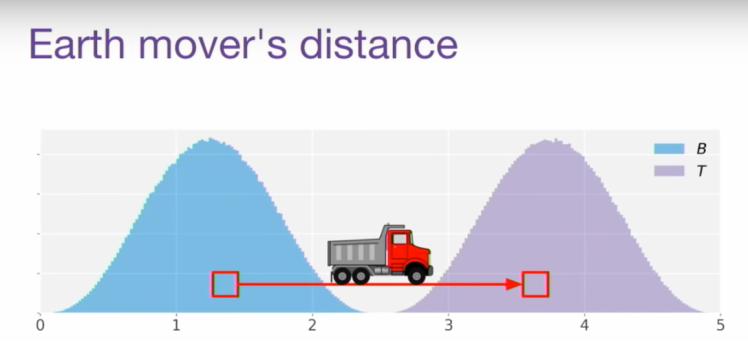 图3 emd。源自网络
图3 emd。源自网络
为什么被称为推土机距离?emd的计算本身来源于线性规划中的运输问题,假设有一系列的土堆s={si|1,...,m} 和一系列的土坑d={dj|1,...,k} ,si表示土堆i拥有的土数量,dj表示土坑j能填入土的数量,cij表示推土机从土堆i到土坑j的单位运输成本,xij表示两地所需的运输量,如何确定最佳运输方案x={xij|i=1,...,m, j=1,...,k},将所有土堆的土填入土坑中,并且总运输成本最低?
通过求解线性规划问题,可以得到最佳运输方案:
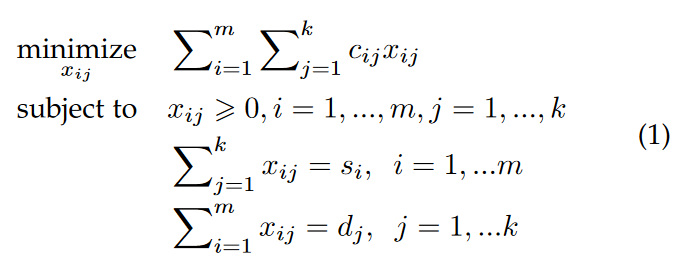
本文将支持集图像和查询集图像对应的特征图分别看成上节中的“土堆”和“土坑”,特征图中的每个像素点都是一个带有权重的结点,而si和dj分别对应相应结点的权重,支持集特征图像素点对应的特征向量为ui,而查询集特征图像素点对应的特征向量为vj,则两个结点间的运输成本cij可定义为: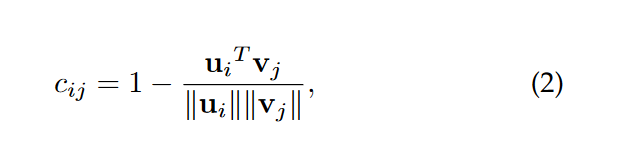
当两个结点ui,vj越相似,这两个向量夹角的余弦值越接近1,cij越接近0;反之则接近1。
通过求解上述的线性规划问题,寻找最优的运输方案x,则两幅特征图(假设特征图大小为hw)之间的相似性得分为:
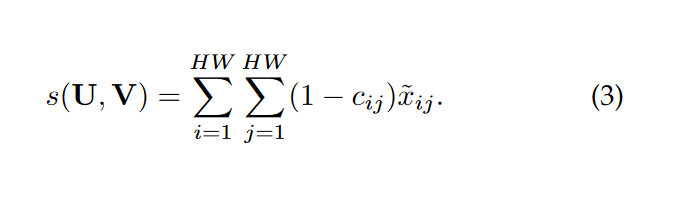 (3)权重生成
(3)权重生成 公式(1)中,权重si,dj非常重要,较大的权重会使相应结点在两个集合的比较中起着更重要的作用。
在采用emd的彩色图像检索工作中,通常颜色占主导地位,我们可以给一张图像中具有更多像素点的颜色分配较大的权重,这样检索的图像可以在视觉上接近查询图像。然而在图像分类任务中,图像分类的特征通常包含许多高级语义信息,不能简单以单张图像的颜色来决定。
对于本文的问题,应该如何确定合适的权重?
为了提取语义信息,我们需要区分前景区域与背景区域,其中前景含有更多有用信息,而背景含有无用信息。以分类数据集imagenet为例,图像的背景区域通常要比前景区域大,因此很难定义前景区域,特别是当单个图像中存在多个对象类别时。在不同的情况下,一个对象既可以是前景,也可以是背景。文章认为,对于小样本分类任务,两幅图像中的共同出现区域更有可能是前景,因此不应该通过单独检查单张图像来确定权重。于是本文提出了交叉参照机制(cross-reference mechanism),该机制使用另一个结构中的结点特征和平均结点特征之间的点积来生成相关性得分作为权重值。si计算公式为(dj与之类似):
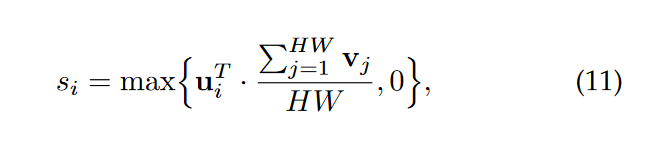
交叉参照机制的目的是在两幅图像中对高方差背景区域赋予较少的权重,而对共同出现的区域赋予更多的权重,从而在一定程度上允许部分匹配。最后,对结构中的所有权重进行归一化,以具有相同的总权重进行匹配:
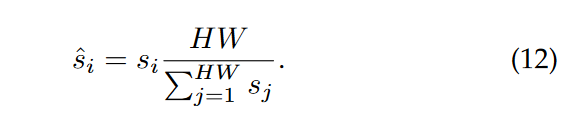
全连接层的学习可以看作是为每个类找到一个原型向量,再使用距离度量对图像进行分类。作者使用emd作为距离函数,对结构化特征表示进行分类,提出了结构化全连接层。结构化全连接层可以在k-shot设置下也能对图像进行分类。
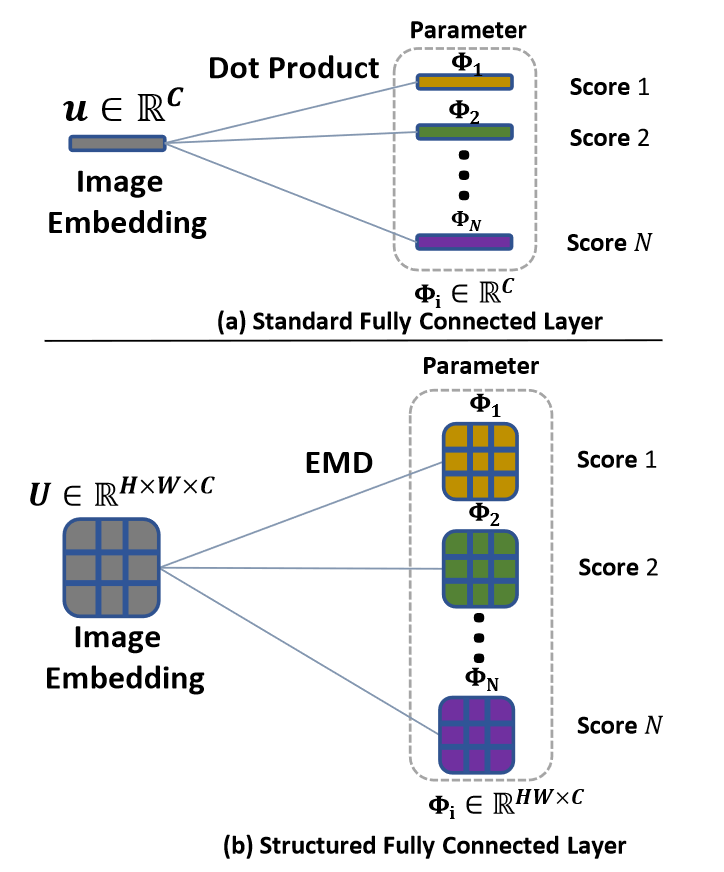 图4 全连接层与结构化全连接层
图4 全连接层与结构化全连接层
作者证明了求解最优运输方案x的过程是可微分的,可以使用梯度下降方式求解将该最优匹配问题嵌入到神经网络中进行端到端学习。详细证明见原文。
在5个流行基准上比较了deepemd与其他方法1-shot 5-way 和5-shot 5-way的性能:miniimagenet、tieredimagenet、fc100、cub和cifar-fs。在多个任务上以显著优势超过了最先进的性能,例如,miniimagenet数据集上1-shot(3.47%)和5-shot(1.43%);tieredimagenet数据集上1-shot(2.77%)和5-shot(1.05%)。
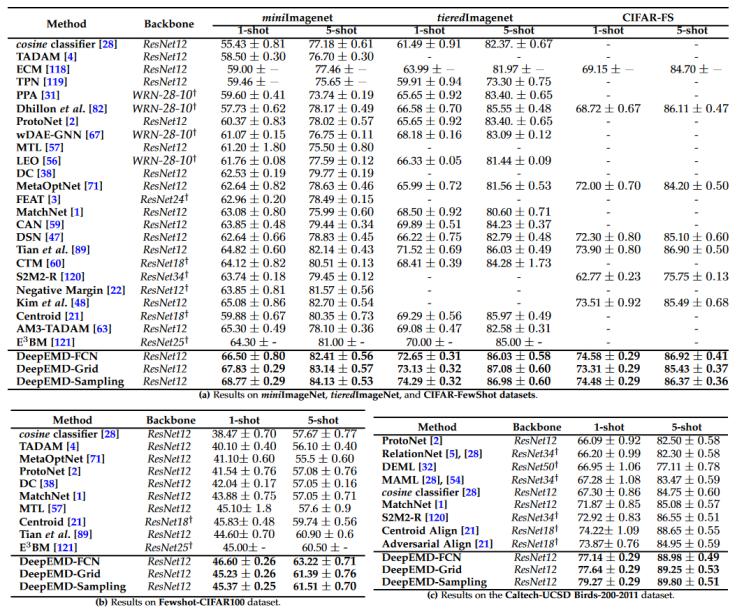 图5 实验结果
图5 实验结果
将小样本分类问题转换成最佳匹配问题,同时利用emd作为距离度量。emd层能加入到网络结构中进行端到端的训练。
提出了交叉参照机制(cross-reference mechanism)来产生emd公式中元素的权重,能有效减少图像中无关区域带来的噪音。
提出了结构化全连接层,能够直接对结构化的图像表征进行分类。
大量的实验表明方法的优异性能,达到了sota。
但是因为其计算时需要求解线性规划方程,导致计算成本很高,实际的训练和测试会很耗时。
撰稿人:叶春锦
指导老师:李景聪






