 1450
1450
 0
0
 2022-12-08
2022-12-08
 2022-12-08
2022-12-08
本篇学习报告的内容来自《film: visual reasoning with a general conditioning layer》,该文章收录于aaai 2018。文章提出了一种特征层面的线性调节方式,在视觉推理(visual reasoning)任务中有很好的效果,可以用于特征合并,例如处理模型的多输入问题。插入film的模型有能力进行各种visual reasoning,包括计数,比较,等等。在某种程度上,可以将film视为使用一个网络生成另一个网络的参数,使其成为超网络的一种形式。
1. 研究背景
visual reasoning(视觉推理)指对图片信息进行分析,并做出一定的推理。其重点在于对于图片内容有逻辑上的理解。例如,普通分类器能够分出图片上是个球还是正方体,而visual reasoning需要做的任务是数出图片中有多少紫色的球,多少黄色的正方体。再比如,一张图片中有一个黄色大正方体,一堆不同颜色的小正方体、小球,小圆柱体,visual reasoning需要找出与大正方体颜色相同的小物体的颜色。概括来说,给出一幅图片和一个问题,visual reasoning就是根据图片回答问题。但是,视觉推理这个任务对普通的深度学习方法来说比较困难,属于一个多步骤、高层次的过程。而film层在clevr的基准上提高了精度,对具有挑战性
2. 实验模型与方法
(1)方法
film层通过学习,自适应性地用仿射变换(线性变化+平移,ax+b x和b为向量)影响着网络的输出。具体来说,film对于输入学习两个函数f和h,并输出γi,c和βi,c :
下标表示第i个输入的第c个特征。用fi,c表示网络的activation,γ和β通过特征仿射变换调节神经网络的激活f,可以表示为:
γi,c = fc(xi) βi,c = hc(xi), (1)
f和h可以是任意函数,比如两个神经网络。实际应用中,这两个函数可以看作一个函数,输出一个向量,因为f和h共享参数对训练有帮助。这个合体后的函数就称作film generator。整个大网络模型叫做feature-wise linearly modulated network(film-ed network)。film generator可以对film-ed network的feature maps特征图进行操作(放缩、提高或者下降域值(当跟在relu后边时候))。对于cnn来说f和h根据不可知的空间位置,调节激活每个特征图分布。
film(fi,c|γi,c, βi,c) = γi,cfi,c βi,c. (2)
(2)模型
一个cnn的单一film层如图1所示。
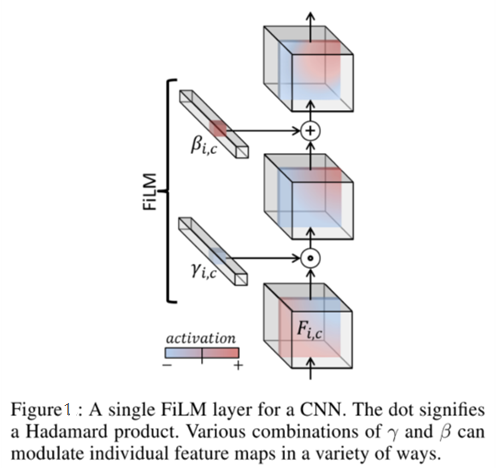
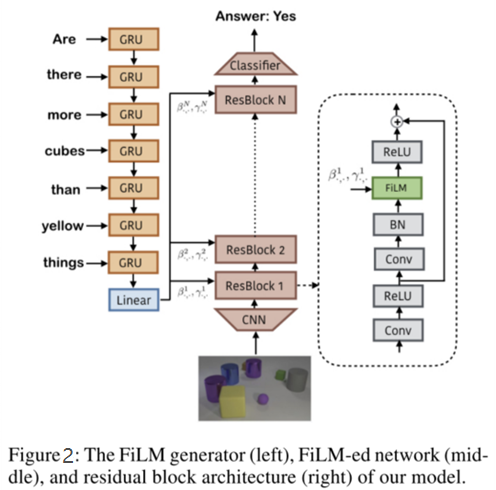
将问题用gru编码后得到的表示作为film的输入,通过两个神经网络学习(和)得到缩放和偏差,接着对cnn学到的中间特征做仿射变换。γ和β的各种组合可以以各种方式调节单个特征图。film会插入到每一个resblock中,对每一层cnn学到的特征进行modulation。点表示阿达玛德积。阿达玛德积不同于传统矩阵相乘计算方式,它是对应矩阵元素相乘,值得注意的是两个相乘的矩阵必须行列数相同。film模型如图2所示。
 阿达玛德积运算过程如图3所示。
阿达玛德积运算过程如图3所示。
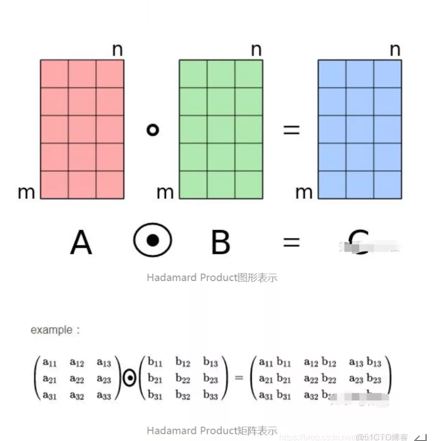
figure3:hadamard product
film模型由一个film生成语言管道和一个film生成视觉管道组成。即两个部分:理解问题(nlp),理解图片(cv)。
3. 实验
实验部分可查看原文。
论文:https://arxiv.org/abs/1709.07871
代码:https://github.com/ethanjperez/film
4. 实验结果与总结
film在clevr数据集上达到了新的整体水平,超过了人类和以前的方法,其中包括那些使用明确的推理模型推理、监督学习又或是数据增强的方法。该结构由于其良好的鲁棒性,以及小样本环境下的能力,被应用到一些小样本分类工作中。比如simple cnaps,一种改进小样本视觉分类的方法,在特征提取部分就使用了resnet18 film层。另外,该模型只是一层网络结构,故没有太多耦合问题,可以自己搭积木,应用到不同网络中去。
撰稿人:杨叶泽盛
审稿人:李景聪






